スキーマの自動移行が必要な理由
スキーマの自動移行が必要な理由
スキーマの変更は、データパイプラインを完全に中断させる可能性がありますが、
自動データ統合であればこの問題を解決できます。
2020年6月11日
現代のクラウドベースアプリケーションは、SaaSプロバイダーが新機能を追加する、包括的データモデルを構築するなどの理由で、絶え間なく変化を続けている状況です。一般的なSaaSのAPIエンドポイントは、定期的な更新により、新たなカラムやテーブルの作成、またスキーマ全体の根本的な再編成などの変更を、一般に公開されるデータに反映します。
このような更新作業は、従来のETLデータパイプラインを完全に中断してしまう可能性があります。目的が非常に限定されたデータ設定に依存する抽出および変換のスクリプトは、予想外の要素に遭遇すると機能停止します。つまり、パイプラインがロードの段階に到達しないということです。通常、このような変更に対応するためには、データパイプラインを完全に再構築する必要があります。データ統合プロジェクトに関わった経験があれば、こういった場合に要する作業時間(および精神的苦痛)についてよくご存知のことと思います。
アナリストの視点からすると、このような中断はダウンタイムを意味する他、同期に一定時間の遅れが発生するため、データが陳腐化するということでもあります。データエンジニアやIT担当者にとっては、これはSLA達成に対する新たな障害が発生したことを意味します。
サイクルを断ち切る
この課題を解決するには2つの方法がありますが、いずれもETLというよりELTに関係します。まず、単純な手法としては、プロセスの「EL」の部分に注目します。厳選した生データを抽出しロードするシステムを構築すると、基礎となるデータモデルに依存しないシステムとなります。こうすることで、ソースでスキーマが変更されるたびにアナリストが再確認可能なレコードのデータリポジトリを構築することができます。
課題を解決する2つ目の方法は、1つ目の方法をより改善させたものです。シーケンスはELTのままですが、すべてのプロセスを自動化し、サードパーティに委託します。サードパーティは、正規化されたスキーマを開発するために、あらゆるデータソースの基礎となるデータモデルを詳細に理解し、そのデータパイプラインを構築後も維持することを役割としています。
Fivetranでは、スキーマの変更をソースからお客様のデータウェアハウスに自動的、段階的、包括的に伝達します。これは状況に応じ、いくつかの方法で対応します。
1.ソースに新しいカラムが追加された場合、変更を検出し、データウェアハウスに同じカラムを追加します。また該当する場合はデータも入力します。
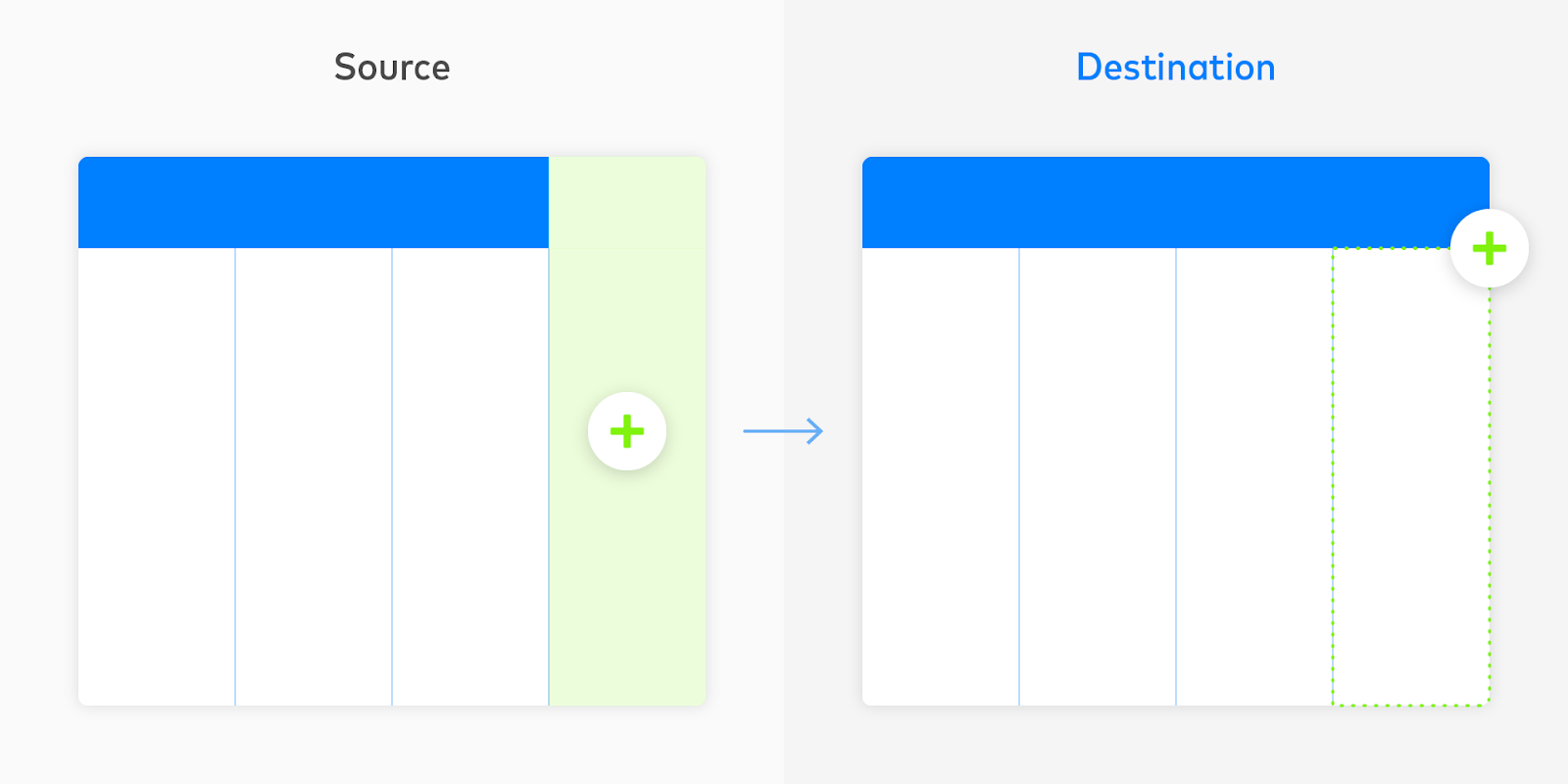
2.カラムが削除された場合、データウェアハウスから完全に削除するのではなく「ソフト削除」し、将来のレコードをNULL(空値)とすることで、古いデータを過去の参照として残します。

3.カラムのデータ型が変更された場合、古いカラムを保持し、新旧両方のデータに対応するデータ型を持つ新しいカラムを作成することにより、新旧いずれのデータも劣化させることなく受け入れるよう努めています。こうすることで、そのテーブルからビューを作成できます。

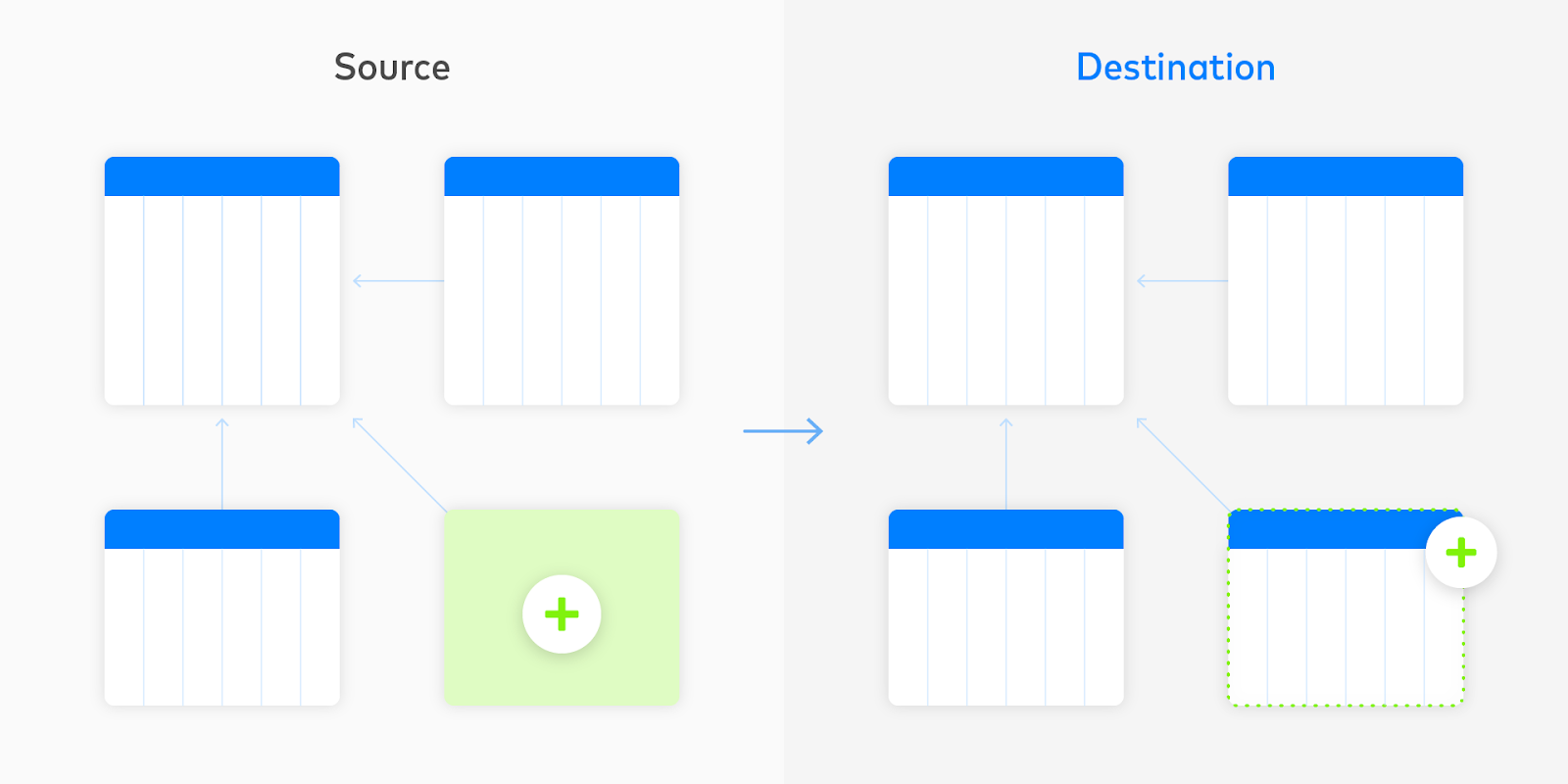
4.ソースに新しいテーブルが追加された場合、他と同様に同期を開始します。
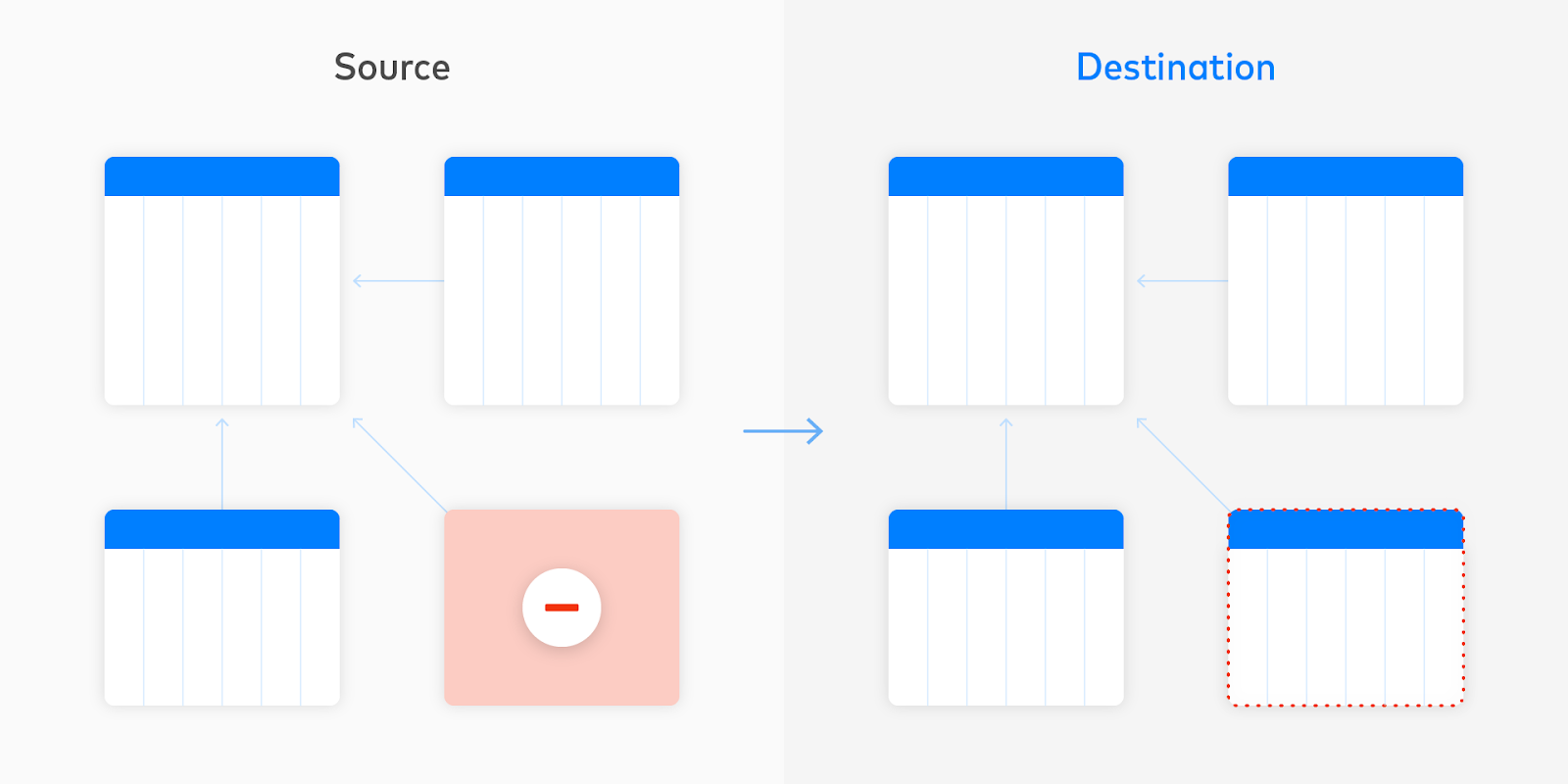
5.ソースでテーブルが削除された場合、お客様のデータウェアハウスには手を加えません。
つまり、ソーススキーマに加えられたすべての変更は、即座に、そして劣化させることなく、レコードのデータリポジトリに複製されます。この方法により、ソースの上流で行われた変更の結果として、お客様のデータパイプラインにダウンタイムが発生しないようにしています。
スキーマの移行自動化によりデータ統合のワークフローがどのように改善されるかを実際にご体験いただくには、無料トライアルにお申し込みいただくか、製品スペシャリストにお問い合わせください。



.svg)
.svg)
.svg)